Study of Privacy-Preserving Techniques for Machine Learning
About the Project
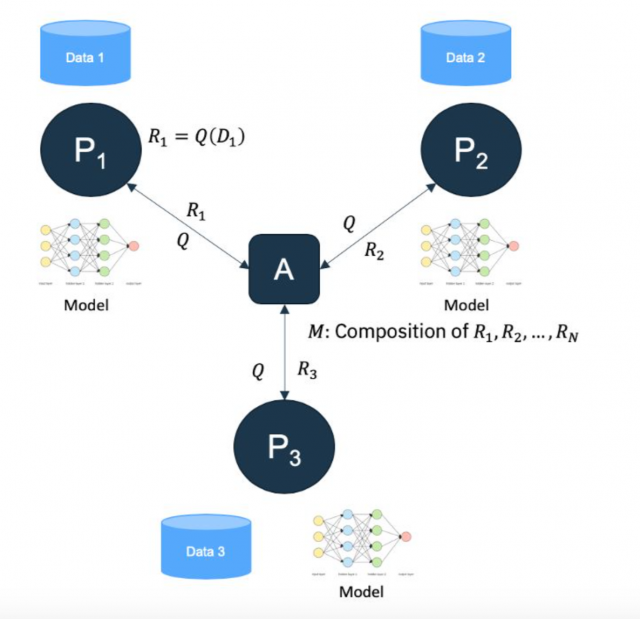
As more sensitive data continues to be collected on each person, it is important to understand the extent to which privacy can be preserved while still learning from general populations. While many theoretical models have been discussed in current work, there is a lack of actual investigation of potential models. Choudhury et al. explored a combination of federated learning and differential privacy, but this paper was not comprehensive and left a lot to be desired. We will continue this work by investigating more variations of models that use differential privacy, federated learning, and the two working together. For each model, we will compare prediction accuracy and privacy preservation, which will hopefully lead us to improved models. In the end, we hope to learn more about the extent to which successful machine learning can preserve privacy, which will allow us to suggest better solutions to machine learning problems in a variety of disciplines.
Therefore, in this project, we are planning to present a comprehensive study of the relationship between accuracy and privacy in privacy-preserving machine learning models, namely those that use decentralized learning and differential privacy. The contributions of the project are summarized as follows:
- Identify what levels of differential privacy can be used in machine learning models while still having competitive accuracies
- Explore extensive combinations of privacy preserving techniques on machine learning models
- Investigate how different machine learning models are affected by privacy techniques
- Explore how different datasets behave under varying privacy models
- Summarize the outcomes of all models
Student Team
- Max Barshay, Statistics
- Flo Costa, Computer Science
- Lindsey Henry, Computer Science
Mentors
- Dr. Phoenix Fang, Computer Science